标题翻译:复合交通走廊中浮动车轨迹实时识别方法
作者:Yu Mei, Keshuang Tang*, Keping Li.
已见刊于:Transportation Research Part C: Emerging Technologies. Vol. 57, 2015, pp. 55-67.
https://doi.org/10.1016/j.trc.2015.06.008
关键词:半监督学习、浮动车轨迹、复合交通走廊、城市快速路
利用浮动车系统进行交通观测被视作是非常有前景的技术之一,中国的大型城市(如北京、上海)也对此进行了大规模的部署。目前,浮动车系统主要由装备了GPS的公交与出租车组成,其上传轨迹点以一定频率的GPS坐标的形式呈现,轨迹点之间的间隔通常在10~20秒。而在这些中国大城市的道路系统中,有较高比例的高架快速路与地面道路平行,即复合交通走廊(如图1所示)。在这种情况下,若没有准确的高差数据与3D地图支撑,我们通常难以对位于高架路与地面道路的浮动车辆进行区分。
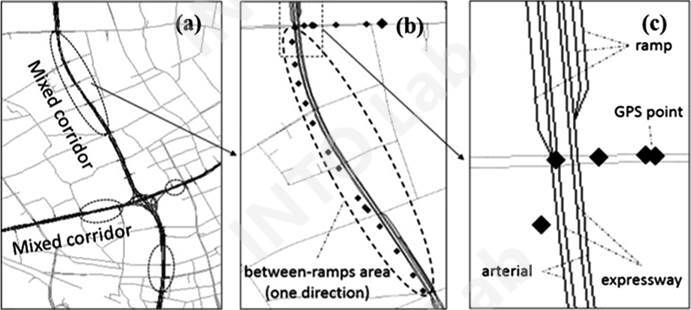
图1 复合交通走廊示意图
针对该问题,现有的地图匹配算法要么采用了基于复合走廊拓扑关系的规则式判断,要么在高架路车速更高的假设下采用速度阈值来进行识别。前者通常在离线应用中使用(需要一段时间的完整轨迹),但由于拓扑关系能提供的辅助信息十分有限,其只能只识别一小部分的轨迹;后者则可以离线或者在线使用,但速度阈值是一个难以确定的参数,在拥堵状态下高架路与地面道路的速度差异并不显著,其阈值的确定更是需要大量历史数据。
因此,针对现有方法中的若干不足之处,本文提出了三种改进的半监督聚类算法,即:约束K-Means(CKM)、种子K-Means(SKM)和半监督模糊C-Means(SFCM)算法。所提出的算法能够利用拓扑关系判断来发挥半监督学习技术的优势,在水平GPS数据的基础上优化传统半监督学习技术的预标签样本和初始聚类中心的选择。
其中,CKM和SKM算法都是基于K-Means的聚类算法,这两种算法通过利用预标签样本来优化初始聚类中心。其中,预标签样本则是根据(1)地图匹配中基于拓扑关系的规则判断法以及(2)动态平均停留时间阈值所获得的(如图2所示)。这两个算法的核心区别在于,CKM算法在聚类的迭代过程中保持了原始类别的标记样本,而SKM算法则没有这个约束。SFCM算法则借鉴了模糊逻辑算法、引入了隶属函数来描述样本的隶属度,并在聚类迭代的过程中不断更新聚类中心和隶属函数。
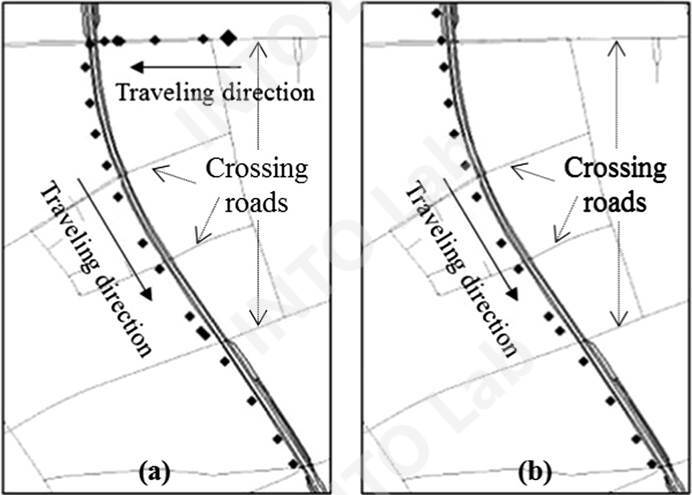
图2 基于拓扑关系对部分样本进行预标签
本文所提出的算法分别在1.7公里长的上海南北高架段以及0.85公里长的内环段上进行了验证,并根据走廊长度、覆盖的交叉口数量、时间段与拥堵状态信息将验证划分为了四个场景(见图3)。结果表明,SFCM算法在非拥堵状态下能实现接近100%的聚类纯度、在拥堵状态下也能实现高于80%的聚类纯度,相较于传统的K-means算法有20%以上的优化幅度。CKM的表现略逊于SFCM,但其具有更快的收敛速度,更适用于在线应用。此外,本文对算法参数进行了敏感性分析,研究参数取值与历史数据对算法结果的影响。
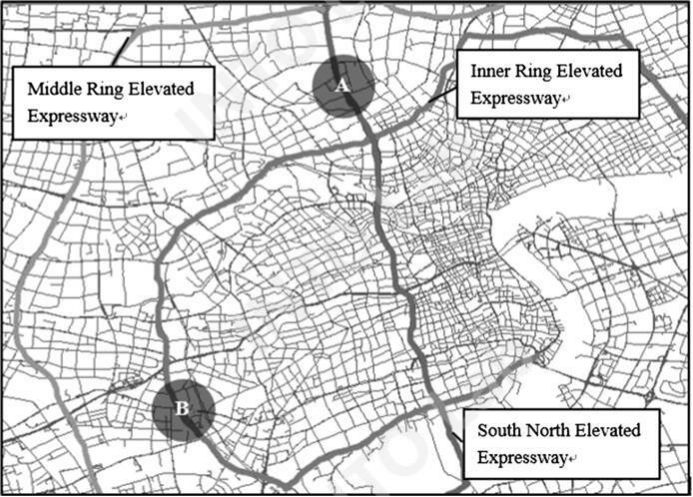

图3 验证场景及参数
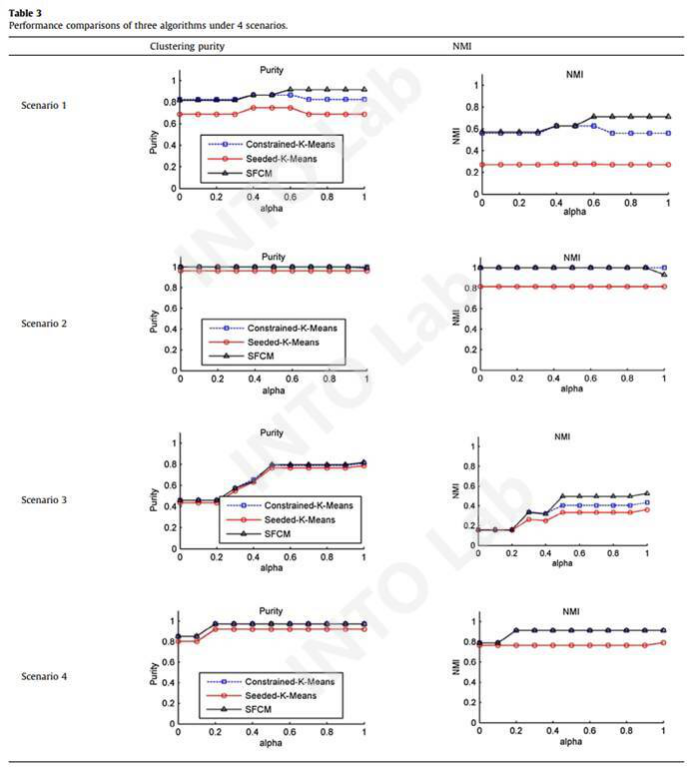
图4 验证结果
本文的研究成果既能够用于离线应用,也能够用于在线应用。对于在线应用场景(如:基于浮动车轨迹的短时交通状态估计),本文提出算法可以按照5分钟粒度运行;对于离线应用场景(如:OD估计、长时交通状态估计),本文算法所识别的轨迹可长时叠加后进行进一步的交通状态与路径分析。

